MhdeiV agewmetrhtoV eisitw
Postmoderne museales Schatzkästchen
Eine Analyse der Museumsdatenbank GNOSARCH
von Dr. sc. math. Hartwig Thomas
10. Oktober 1994
Augangslage
Ich bin von Herrn Beni Müller auftrags der Furrer+Partner AG gebeten worden, das System GNOSARCH vom Informatikerstandpunkt aus zu beurteilen.
Als Grundlagen für die Beurteilung stand mir eine Diskette zur Verfügung, auf welcher sich verschiedene Textdateien mit Ansätzen zu einer Dokumentation als auch etwelcher Programmquellkode (Clipper) befindet.
Die Programmteile waren nicht in funktionaler Vollständigkeit vorhanden. Auch fehlen die notwendigen Datenbankeinrichtungen. Es war also unmöglich, auch nur Teile des Programms im Einsatz zu sehen.
Die Stückchen Programmquellkode zeichnen sich aus durch Abwesenheit jeglicher Dokumentation und Kommentare. Dies, zusammen mit der bruchstückhaften Benutzerdokumentation, die von Sätzen strotzt, wie Ein Wort ist eine verbalverwendbare Abstraktionseinheit, die auf eine Sache, ein Konzept oder einen Zustand zeigt. [NALL.LTR], ergibt das Bild eines Einmannprogramms, dessen Sinn und Zweck nur im Kopf des Autors einigermassen kohärent existiert, ohne jedoch an die Aussenwelt kommunizierbar zu sein.
Die vorliegende Beurteilung muss sich also weitgehend auf die Beschreibung des Autors (Edward Loring, I&E, Trinity College, Cambridge) von GNOSARCH stützen, soweit diese auf der Diskette vorgefunden werden konnte.
Funktionalität
Was ist GNOSARCH?
An verschiedenen Stellen in der Dokumentation findet man abstruse Definitionen von GNOSARCH, wie etwa: GNOSARCH ist ein intelligentes, nicht biostatisches, elektromagnetisches Wesen gestaltet als postrelationales Wissens-System bestehend aus einer beliebig erweiterbaren Datenstruktur und einer unbeschränkten Anzahl Applikationen und Verwaltungsmodulen. [NALL.LTR] Nur wer es schafft solch einen Satz widerspruchslos zu absorbieren, eignet sich als Benutzer von GNOSARCH.
Anscheinend hat sich der Autor von GNOSARCH zum Ziel gesetzt, mit GNOSARCH die Welt und die Menschen zu imitieren. Gemäss Loring ist die Natur eine sich fortsetzend mutierende Relation [INFRASTR.LTR], bzw. eine sich im Zeit-Raum unaufhörlich mutierende n-dimensionale Eigen-Relation (nHH) und deren Inhalt [NALL.LTR]. Die Menschen sind dynamische Teilrelationen des gleichen Systems [INFRASTR.LTR] und GNOSARCH ist strukturiert als Teilmenge des realen, intelligenten und sich evoluierenden Systems, in welchem wir kausalitäts-beeinflusste und -beeinflussende Wesen arbeiten. [NALL.LTR]
All diesen Definitionen ist gemeinsam, dass es sich um übelsten Hintertreppen-Wissenschaftsjargon handelt, mit Imponier-Altgriechischkenntnissen angereichert und mit Computerchinesisch abgeschmeckt. Die Mischung ist genauestens darauf berechnet, den Phil-I-er mit einem EDV- und Naturwissenschafts-Minderwertigkeitskomplex (s. Zweiweltentheorie von C. P. Snow) terminologisch, philosophisch und psychologisch einzuschüchtern. Dass GNOSARCH Finanzierungsquellen gefunden hat, zeigt, dass dieser Kalkül aufgeht.
Der nüchterne Aspekt der Frage, was GNOSARCH ist, bleibt allerdings unbeantwortet: Es ist nicht eruierbar, aus welchen Dateien und Programmbestandteilen sich das System zusammensetzt, das unter dem Namen GNOSARCH in verschiedenen Museen eingesetzt wird. Weder konnten wir einer Aufstellung dieser Dateien habhaft werden, noch scheint es mit Nummern gekennzeichnete Versionen des Programms zu geben. Gibt es eine Installationsdiskette? Es steht zu vermuten, dass die Frage nach dem Lieferumfang, unbeantwortet bleibt. Das Insistieren in den Definitionen auf Ausdrücken wie "sich unaufhörlich mutierend" etc. lässt uns vermuten, dass es sich bei GNOSARCH um ein "Work in progress" handelt, das noch nicht fertig ist (Die Entwicklung geht weiter. GNOSARCH wird nie 'fertig' sein. [NALL.LTR].) Es ist denn auch von einer Verteilte Entwicklungsversion [INFRASTR.LTR] die Rede. Von einer Auslieferungsversion steht nirgends etwas.
Was soll GNOSARCH?
Leider fehlen sämtliche Angaben zur intendierten Funktionalität von GNOSARCH. Es ist also nur aus der Beschreibung der Datenstrukturen und der Eingabemsaken erschliessbar, was das Programm bezweckte.
Wir gehen im weiteren insbesondere auf die Beschreibung dieser Datenstruktur ein. Loring selber möchte, dass er nicht anhand der Gestaltung von Eingabemasken beurteilt wird. Wenn die AnwenderInnen nur über Bildschirm-Masken und Karteikarten meckern, ist es dem Informatiker klar, dass sie vom System nichts verstanden haben. Die heutige Bewegung der Konsum-Informatik beschäftigt sich hauptsächlich mit der Verpackung. Hinter der aufwendigen Verpackung versteckt sich nicht selten eine äusserst dürftige Struktur und eine fragwürdige Logik. [...] Wir möchten das System, in welchem wir uns befinden, oder Subsysteme davon, möglichst genau und mit einem hohen Wahrheitsmodulus vermessen und beschreiben. [INFRASTR.LTR]
Wir entnehmen diesem Zitat, dass GNOSARCH nach Meinung seines Autors dazu dienen soll, die Welt zu vermessen und zu beschreiben. (Wir haben oben gesehen, dass "System, in dem wir uns befinden" bei Loring eine Chiffre für Natur oder Universum darstellt.)
Loring belehrt uns, dass
a n a l u w auflösen bedeutet. Die vorliegende Analyse muss also prüfen, inwieweit es sich beim Thesaurussystem GNOSARCH um eine Schatztruhe handelt, denn q h s a u r o V bedeutet ja Schatz. Mangels vorhandenen Angaben in der Dokumentation müssen wir und beim Versuch, herauszufinden wozu dieses Programmsystem dient, dem Risiko aussetzen, dass es dem Informatiker klar wird, dass wir nichts verstanden haben.
Was ist ein Thesaurus?
Der Tresor GNOSARCH ist eine Datenbank, in der die Welt abgebildet wird. Dieser enthält verschiedene Thesauri. THESAURI sind Listen von Begriffen, die im GNOSARCH zugelassen sind. [...] Hier nennen wir sie nach den Grundbedeutungen. [NALL.LTR].
In GNOSARCH gibt es zwölf (NALL.LTR) bzw. dreizehn (INFRASTR.LTR) solche Listen. Die in GNOSARCH zugelassenen Begriffe entsprechen recht wahllos gewissen Kategorien, denen man die inventarisierten Museumsobjekte zuordnen kann (ORT, BAU, TYPOLOGIE ('DING'), CHRONO, ACTORS, MATERIAL, TECHNIK, IKON, EIGENSCHAFT, POLITISCH, ENOKULTUR, PERSON, FIRMA [beschrieben in NALL.LTR]).
Die Tatsache, dass die Begriffe hier "nach den Grundbedeutungen" genannt sind, spiegelt sich in einer durchgreifenden Tendenz zur Hypostasierung der Begriffe im gesamten System. Man wird zwar mehrfach gewarnt, die Namen der Dinge nicht mit den Dingen selber zu verwechseln, andererseits sind alle Beispiele so angelegt, dass die Namen der Dinge in den Synonymthesaurus verbannt werden, während die Thesauruseinträge für das Ding an sich stehen. Dementsprechend ist in der Dokumentation auch durchgängig von Entitäten die Rede. GNOSARCHs Thesauren werden als Entitätsmengen bezeichnet (von lateinisch "ens", das Seiende). Ganz verschämt wird nebenbei erwähnt, dass diese als Datensätze mit Feldern implementiert sind, wenn auch anderswo gegen dieses "Felddenken" der Projektmanager gewettert wird und gleichzeitig die Einzigartigkeit von GNOSARCH als 'post-relationales' System [NALL.LTR] angepriesen wird, vereint doch die GNOSARCH-Philosophie die Eigenschaften des Netzmodells mit jenen des Relationsmodells. [NALL.LTR]
Besitzstanddenken
GNOSARCH kennt für jeden Thesaurusbegriff einen (oder null) "Besitzer". Damit wird der Begriffswelt eine hierarchische Struktur aufoktroyiert. Dies wird anhand der Teilmengenstruktur des Orte-Thesaurus (Stadt Basel liegt im Kanton Basel liegt in der Schweiz) plausibel gemacht. Es dürfte aber eher dem Bedürfnis nach Taxonomie beim Zugriff auf die gespeicherten Daten entsprechen. Schliesslich sind auch traditionelle Thesauren, wie etwa Roget's Thesaurus oder die Macropedia der Encyclopedia Britannica ein hierarchisches Modell der (Begriffs-)Welt.
Die Thesauren sind also alle baumförmig strukturiert:
Was ist ein LINK?
Schon bei den Orten ergibt sich die Schwierigkeit, dass nicht alles einen klaren Besitzer hat, sondern dass manche geographische Regionen nur partiell zur einen oder anderen Region gehören (Bsp. ""Bern und "französisches Sprachgebiet" in INFRASTR.LTR). Als grosse Erfindung verkauft uns GNOSARCH für solche Fälle die grosse Erfindung der LINKS. Es handelt sich einfach um eine zweistellige Relation, wo jedes Element eines jeden Thesaurus mit jedem anderen Element in jedem anderen Thesaurus verknüpft werden kann. Wenn man sich die Thesaurusentitäten als Punkte denkt, dann kann man sich Links als Verbindungsstriche zwischen je zwei solchen Punkten vorstellen. Die Links werden an einem Ort "horizontale" Links genannt, weil sie zur oben aufgeführten "vertikalen" Hierarchiebeziehung orthogonal sind.
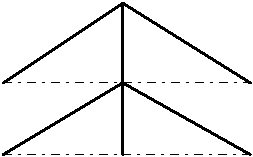
Links können in GNOSARCH beliebig eingefügt werden. Diese Verkabelung mittels binären Prädikaten entspricht gemäss dem Autor dem assoziativen Denken der Menschen. Diese Erfindung der beliebigen Vernetzung entstammt der Frühzeit der Informatik. Unter dem hochtrabenden Namen "Netzwerkmodell" wird uns diese unübersichtliche Verknäuelung beliebt gemacht.
Der Autor erbarmt sich zwar derer, welche die Aussagenlogik nicht verstehen (Wissen Sie was das exclusive "oder" <XOR> bedeutet? Wenn Sie diese Logik nicht wirklich beherrschen (das ist keine Schande), dann FRAGEN SIE! [INFRASTR.LTR]), ist aber im Prädikatenkalkül weniger zuhause. Deshalb hat er uns wohl auch mehrstellige Relationen erspart. Man hätte ja etwa eine dreistellige Geschenkrelation einführen können ("Objekt X ist Papst Y von König Z geschenkt worden", oder "Objekt X wurde dem Museum Y von Sammler Z überreicht."). Diese würde sich allerdings so schlecht mit dem Bild der Striche zwischen den Punkten vertragen, dass sie den Rahmen des GNOSARCH-assoziativen Denkens sprengen würde.
Die zweistellige LINK-Relation ist in GNOSARCH als einfache Liste realisiert, wo ein Datensatz im wesentlichen aus zwei Feldern besteht, nämlich den IDs der beiden verknüpften Begriffe. Die "SPARSE MATROID-Technologie" (GNOSARCH-Datastruktur == "SPARSE MATROID") [INFRASTR.LTR]) kann zur Speicherung solcher binärer Relationen verwendet werden. Es steht aber zu vermuten, dass diese binäre Relation einfach als xBase-Datei realisiert ist und somit der verwendete Algorithmus einfach der Clipper-Algorithmus ist.
Der Nachteil einer beliebigen binären Verbindung von Allem und Jedem besteht darin, dass zwar zwischen je zwei Begriffen ein Kettenglied (Link) hergestellt werden kann, dass dieser Verbindung aber keine Bedeutung zugeordnet ist. In der realen Welt ist grundsätzlich alles irgendwie mit allem zusammenhängend. Es ist nicht sehr nützlich, wenn man deswegen zwischen je zwei Objekten eine Verbindung herstellt. (Vorschlag GNOSARSCH-Dokumentation: Louvre - Pyramide, Pyramide - Mexico, Mexico - Tamale, …).
Nützlicher würden binäre Relationen dann, wenn man die verschiedenen Verbindungsstränge zwischen den Objekten mit verschiedenen Bedeutungen versehen würde. Wenn etwa rote Striche bedeuten würden, "gehört zur selben Kultur" und grüne Striche heissen würden, "beide Objekte sind an der selben Fundstelle gefunden worden", dann könnte man je nach Interesse das rote oder grüne Geflecht verfolgen. Die Semantik der Relationen interessiert aber den GNOSARCH-Autor nicht, anscheinend ist sie unwesentlich für sein assoziatives Denken. Vielmehr setzt er auf die postmoderne Beliebigkeit der Verknüpfbarkeit von Allem mit Jedem die er nicht müde wird, immer wieder hervorzustreichen. (Neue Verbindungen können beliebig erstellt werden [INFRASTR.LTR].)
Der ganze Witz eines Thesaurus besteht im Aufbau eines kontrollierten Wortschatzes für die systematische Suche nach Einträgen. Die völlige Beliebigkeit der Einführung neuer Verknüpfungen unterminiert diesen Vorteil eines systematischen Thesaurus.
Synonyme
Da die Suche nach Objekten irgendwo bei der Eingabe doch immer wieder bei den eingetippten Wörtern oder Wortbestandteilen landet, kommt GNOSARCH nicht darum herum, sich den Namen der Dinge zuzuwenden. Hier haben wir das einzige Beispiel der Verwendung von Links, wo die Semantik vom System festgelegt ist. Zu jedem Thesaurus gibt es die Menge der hypostasierten Entitäten (etwa die Gemeinden der Schweiz im Orte-Thesaurus) als auch die Liste der Synonyme (die Namen der Gemeinden der Schweiz). Zwischen den Entitäten und den Namen besteht eine zweistellige Relation. Diese kann 1-n oder n-1 sein. D.h. ein Name kann für mehrere Entitäten stehen oder mehrere Namen können für dieselbe Entität stehen. Ob auch n-n zugelassen ist, geht aus den Beschreibungen nicht hervor.
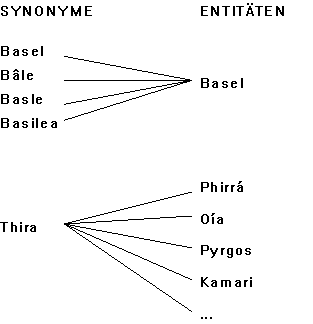
Hier ist die Semantik der binären Relation klar: Das Synonym X steht (teilweise) für die Entität Y.
Beurteilung
Zusammenfassung
GNOSARCH ist eine bescheidene relationale Datenbank mit 13 Thesauri (Schlagwortregistern), deren Begriffe in eine hierarchische Struktur gegliedert werden können, deren Begriffe "assoziativ" verknüpft werden können, mit 13 zugehörigen Synonymverzeichnissen, die mit den Begriffen verknüpft werden können.
Als "Ariadnefaden" durch das System wird der Suchpfad gespeichert, weil man sich im Linkknäuel leicht verheddern kann, wie dies heute bei allen Hypertextsystemen zum Standard geworden ist.
Die eigentliche Nutzdatenbank ist die Liste der inventarisierten Museumsobjekte. Diese sollen über die Verknüpfung mit den Thesauruseinträgen zugänglich gemacht werden.
GNOSARCH hat besondere Mühe mit kontinuierlichen Masszahlen, wie Zeit (Chrono-Datenbank) oder Ausmasse der Objekte (N.B.: Der Informatiker distanziert sich von dieser Einreihung, zu welcher er gezwungen wurde. [NEUOBJ.LTR])
Kampf dem Benutzer
GNOSARCH steht mit einem Teil seiner Benutzer auf Kriegsfuss. (der sog. XBase-Cowboy kommt trotz allen Warnungen überall vor und richtet Schäden an). [SETFILES.LTR] Es ist wahrscheinlich, dass gewisse extra-kluge Anwender sogar (absichtlich und mit guten EDV-Kenntnissen) Abstürze produzieren könnten. [NEUOBJ.LTR] Versuchen Sie nicht irgendwelche exotischen Controlzeichen einzugeben und betätigen Sie keine Tasten, deren Funktion Ihnen nicht vertraut sind. [INFRASTR.LTR]. Manchmal bedarf es sogar der förmlichen Ermutigung, doch etwas einzugeben: Tippen Sie den zu suchenden Wert ein und <ENTER>. Ihnen kann nichts böses geschehen.
Gegen Oberflächlichkeit
Für die Kosmetik und die Benutzerführung hat GNOSARCH, das sich der reinen Wissenschaft geweiht hat, nur Verachtung übrig. Selbst die Hauptmaske ist in jeder Hinsicht beliebig konfigurierbar: Die erste Maske ist eine einfache Auswahlliste. Die Liste kann in einer beliebigen Reihenfolge und mit beliebigen Bezeichnungen für die 13 Datenmengen konfiguriert werden. Auf das und andere rein kosmetische Äusserlichkeiten werden wir später zurückkommen. [INFRASTR.LTR] So erklären sich denn wohl Thesaurusbezeichnungen wie religio, irratio oder Enokulturelle Bedeutung (hat wohl doch nichts mit Enologie zu tun). Auffallend ist die lockere Mischung zwischen hypostasierten "Entitäten" und Thesauren mit Bezeichnungen, wie Eigenschaften oder Adjektive.
Behauptungen
In der Dokumentation zu GNOSARCH wird eine Reihe von Behauptungen aufgestellt, welche die Unersetzbarkeit von GNOSARCH beweisen sollen und welche sämtliche völlig unhaltbar sind:
LINKS
Die Struktur des Systems GNOSARCH ist eine komplexe Form des sog. "ENTITY RELATION MODEL". Wir stellen fest, dass dieses Modell nur selten im PC verwendet wird und haben es in der "Mac World" noch nicht gesehen. Sog. "Programmgeneratoren" bzw. 4-Generation Sprachen" werden mit diesem Modell nicht fertig. Es muss wirklich ausprogrammiert werden. [INFRASTR.LTR]
Das sog. ENTITY RELATION MODEL ist nichts anderes als das grundlegende Konzept der relationalen Datenbanken. Seit ihrer Konzeption in den frühen Siebziger Jahren wurde dieses Modell von fast allen Datenbanksystemen unterstützt, die sich relational nannten—auf dem MacIntosh und auf dem PC natürlich erst seitdem es diese Maschinen gibt. Es gibt keinen inhärenten Grund, warum gewisse Viertgenerationswerkzeuge nicht dafür eingesetzt werden können, obwohl es sich im vorliegenden Fall vielleicht aus anderen Gründen nicht empfiehlt.
Die älteren, starren Datenmodell, bzw. die meisten sog. Relationsmodelle im PC-Bereich können keine solche Relationen gestalten. Keines kann mit Deskriptoren zu den Verbindungsmengen umgehen. [INFRASTR.LTR]
Es ist richtig, dass ganz frühe Versionen von dBase nicht mehr als eine flache Relation behandeln konnten (vor 1983). Diese Restriktion gehört aber schon seit Jahren der Vergangenheit an. Die Frage, wie man "mit Deskriptoren umgeht" ist eher eine Frage des datenbankdesigns als des verwendeten Datenbanksystems. Deshalb gelingt es dem GNOSARCH-Autor ja auch, sein System in einer bescheidenen traditionellen Datenbankumgebung wie Clipper zu realisieren.
Wir verwenden Clipper Version 5.0x. Die Arbeitsmenge wäre in einer anderen Programmiersprache zeitlich/wirtschaftlich nicht zu bewältigen. Jedoch können wir Routinen in "C" und Assembler beliebig einbinden. Bis jetzt hat noch niemand die Grenzen von Clipper erreicht. [INFRASTR.LTR]
Die ökonomische Abschätzung, inwiefern Clipper die einzige Programmierumgebung ist, mit der die Arbeitsmenge zeitlich/wirtschaftlich zu bewältigen ist, wird leider nicht belegt. Erfahrungsgemäss steckt die Hauptarbeit bei solchen Thesaurussystemen in der sorgfältigen Strukturierung des Systems, in der Abklärung der benötigten Funktionalität, im Datenbankdesign und in der Oberflächengestaltung. Diese Arbeiten sind weitgehend unabhängig davon, welche Programmierumgebung verwendet wird. Die Grenzen von Clipper sind schon von vielen Anwendern erreicht worden. Insbesondere gibt es ärgerliche Beschränkungen von maximalen Arraygrössen auf 64 kByte in der DOS-Version. Da in GNOSARCH anscheinend Arrays für die Darstellung von Fundstellenlisten bei der Suche nach Synonymen verwendet werden, ist zu erwarten, dass das System maximal 64'000 Synonyme anzeigen kann. Die Eingabe von "*.*", wie sie etwa in INFRASTR.LTR beschrieben wird, empfiehlt sich also nur für Museen mit einer beschränkten Anzahl von Objekten. Dies ist nur eine der vielen Beschränkungen von Clipper, die übrigens zum grossen Teil jedem Clipper-Handbuch entnommen werden können.
Die meisten Datenbank-Vorschläge, die wir von Nicht-Informatikern (meist der Fall bei den Projektleitern) bekommen, sprechen von "Feldern" und bestehen nur aus Listen von solchen ohne Rücksicht auf deren Strukturierung. Diese "Felder-Theorie" stammt aus einer Vergangenheit, in welcher das Relationenmodell noch nicht bekannt war, dh. aus der vor-PC-Zeit. [INFRASTR.LTR]
Es ist richtig, dass auch nicht-relationale Datenbanken mit dem Wort "Feld" operiert haben. Mit der Einführung des Relationenmodells wurden dann aber typischerweise die Einträge ("Entitäten") als "Datensätze" und die Attribute als "Felder" bezeichnet. Dies ist heute allgemein üblich und deutet nicht auf eine Verwurzelung in der Informatiksteinzeit hin.
Ältere, heute veraltete Datenstrukturen ("Netzwerkmodell", "Hierarchiemodell") verwenden diskrete Felder, die durch eine starre Struktur verbunden sind. [INFRASTR.LTR]
Tatsächlich wurden diese beiden "Modelle" in der Anfangsphase polemisch von den Erfindern der relationalen Datenbanken zu recht als antiquiert hingestellt. Es fällt auf, dass die einzigen Strukturen in GNOSARCH das Netzwerkmodell (LINKS) und das Hierarchiemodell (Besitzer) sind. Die relationale Struktur des Datenbanksystems ist erfolgreich eliminiert worden. Insofern darf sich ein solches System denn auch post-relational oder relational/assoziativ nennen.
Ein Merkmal solcher Systeme ist, dass sie "Invertiert" bzw. "Indiziert" werden müssen, bevor neue Eingaben abgerufen werden können. [INFRASTR.LTR]
Tatsächlich müssen für Volltextsysteme "invertierte Indizes" hergestellt werden. Diese Indizes können einfach aktualisierbar sein, wie Datenbankindizes oder sie müssen jeweils in einem grossen Batchjob aktualisiert werden. Datenbankindizes, wie sie auch von GNOSARCH verwendet werden, können ebenfalls einfach aktualisierbar sein oder nicht. Es ist tatsächlich zu prüfen, ob man für die Basler Museen nicht besser ein Volltextsystem einsetzen würde. (Übrigens wird "indiziert" im Deutschen von Ärzten auf Medikationen angewendet, wenn sie "angezeigt" sind. Die Herstellung eines Index nennen wir "Indexieren".)
Beurteilung
GNOSARCH ist ein unfertiges und konzeptionell unausgegorenes Konglomerat von Clipper-Programmen. Es steht zu befürchten, dass ein Grossteil des Aufwands, der in die Erfassung der Daten für Clipper gesteckt wurde, verloren ist.
GNOSARCH ist ein typisches Produkt, das ohne Analyse der Bedürfnisse der Benutzer hergestellt wurde. Es verrennt sich im Problem der Strukturierung seiner internen Welt. Das zu lösende Katalogisierungsproblem der Museen wäre dagegen in erster Linie ein terminologisches Problem, nicht ein Problem der Taxonomie.
Es ist dringend vom weiteren Einsatz von GNOSARCH abzuraten, da nur so weitere nutzlose Ausgaben gestoppt werden können.
Empfehlung
Den Basler Museen ist zu raten, möglichst bald ein neues System für die elektronische Katalogisierung ihrer Daten in Betrieb zu nehmen. Zur Absicherung des Investitionsrisikos wird empfohlen, dass nur Programme gekauft werden, die fertig sind und einem minimalen Produktestandard hinsichtlich Umfang, Dokumentation und Support genügen.
Solche Programme kann man entweder im Bereich "Lagerbuchhaltung" finden, sofern die administrativen Bedürfnisse überwiegen oder im Bereich "Bibliothekssoftware", wenn die Katalogisierung das Hauptbedürfnis ist.
Da die aufgewendete Erfassungsarbeit der grösste Aufwandposten ist, den ein solches Programm mit sich zieht, ist besonders auf gute und klare Standardisierung der Daten (Zeichensätze) und Schnittstellen (SQL) zu achten, da die Daten sicher länger leben werden, als die heutige PC-Generation.
Der Datenbankdesign müsste bei einem zweiten Anlauf seriös den Benutzerbedürfnissen angepasst werden. Diese müssen genau erhoben werden. Vielleicht entspricht ein Volltextretrieval den Ansprüchen besser. Vermutlich ist ein modernes Hybridsystem das Richtige, das Volltextsuche in langen Textdatenbankfeldern erlaubt und die Einbindung von Bilddaten ermöglicht.
In das neue System ist dann von den GNOSARCH-Daten, was irgendwie brauchbar ist, herüberzuretten.
Der Datenbankdesign ist möglichst pragmatisch zu halten. Statt dem Aufbau komplexer Thesauri ist zu prüfen, wieweit die Volltextsuche die Bedürfnisse abdeckt. Vorhandene nützliche Karteien (Papier) sollten aber in das System integriert werden.
Ein generelles Autorensystem, wie es heute Bestandteil vieler multimedialer Datenbanken ist (DynaBook, Adobe Acrobat) könnte es ermöglichen, dass jeweils einzelne Spezialisten ihr eigenes "Beziehnunsnetz" erzeugen und zu einem Spaziergang durch die Objekte zusammenstellen. Das wäre eine sehr viel nützlichere Einsatzform der Thesauruskonstruktion. Solche Spaziergänge könnten evtl. in Ausstellungen oder auf CD-ROM für Schulen sogar ökonomisch vermarktet werden.
Zum Beispiel kann man heute bestehende Datenbanken mit Visual Basic und Access um eigene Anwendungen und "Views" erweitern. Dabei kommen Datenbankkenntnisse etwa auf dem Schwierigkeitsniveau von dBase zur Anwendung, wie man sie durchaus beim informatikinteressierten Teil der Museumsmitarbeiter vorfinden kann.